
shutterstock
ここ数年、Webブラウザのセキュリティが徐々に厳しくなっている。ユーザーのコンピューターから情報が盗まれたりしないようにするだけでなく、個人情報の流出を防いだり、プライバシーに配慮したりするように、さまざま対策がとられるようになった。
そうした流れの一環として、リファラで流入元URLの詳細が分からなくなるという動きが、先月話題になった(
Web担当者Forum)。Webサイトを運営している人たちにとっては、かなり大きな動きだと言える。
ただ、そうした業界にいない人は、リファラとはそもそも何なのか、どういった影響があるのか、ピンと来ない人も多いはずだ。そこで今回は、リファラーとは何なのか、詳細な情報が得られなくなると、どういったことが起きるのかという話をする。
Webのリファラ(referer)を理解するには、元になる refer という単語の意味から考えるとしっくりと来る。refer は「~に言及する」「~を参照する」といった意味の言葉だ。referrer で「言及する人」という意味になる。
ちなみに本来のリファラは「referrer」という綴りだが、Webのリファラは歴史的に「referer」という綴りになっている(rが1つ少ない)(
RFC 2616)。
では、Webのリファラについて見ていこう。
たとえば「ニュースABC」というWebページで、「動物園ZOO」というWebページを、リンク付きで紹介していたとする。このとき、「ニュースABC」は「動物園ZOO」について言及したわけだ。そして「動物園ZOO」にとって、「ニュースABC」は「言及した人」、つまりリファラ(referrer)になる。

こうした言及元のことを、リファラやリンク元などと呼んだりする(
IT用語辞典 e-Words)。
このリファラを、技術的な観点から見てみよう。
Webブラウザとサーバーのやり取りは、HTTPというルールでおこなわれている。このルールのもとでWebブラウザがサーバーと通信する際は、HTTPヘッダと呼ばれる情報を送る。
Webブラウザからサーバーに送信するHTTPヘッダには、HTTPリファラという情報(Refererという項目)が含まれている。そこには、言及元のURLが記載されており、サーバー側は、どのWebページからやってきたのかが分かる。
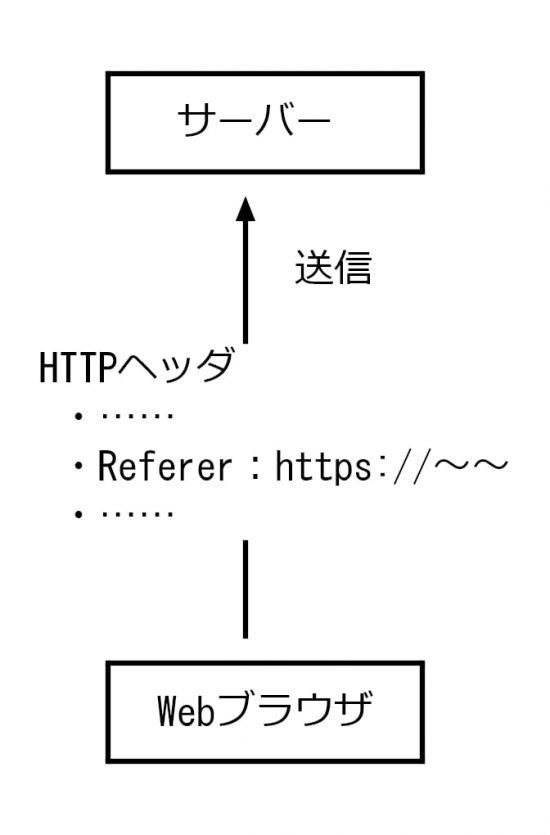
このリファラの情報が得られれば、どういうことが分かるのか、具体例を元に説明する。


